New artifacts explored, and progress report so far!
For the past two weeks, I have been working on the following work-items:
- Learning distributed application development using the ‘Actor’ model, with AKKA.
- Continuing the work on event-driven database replication for Apache Airavata microservices.
- Working with Ajinkya and Amruta on the Distributed Task Execution project.
- Wrote a paper on ‘Distributed Task Execution Framework’ and submitted to the PEARC’17 conference.
Event Driven DB Replication
In my previous blog, I mentioned about using queue based implementation of RabbitMQ for delegating events (messages) from a publisher service to a subscriber service. Note here, a publisher service is one which will forward the db replication request, and subscriber service is one which will have it’s db replicated via events. But after brainstorming, we realized that a topic based implementation of RabbitMQ would fit our use-case well, and also eliminate the necessity to create multiple queues at the db-event-manager side. Better, by altering a few configurations and lines of code, we can mimic the worker-queue functionality as well.
Updated architecture using TOPIC based implementation
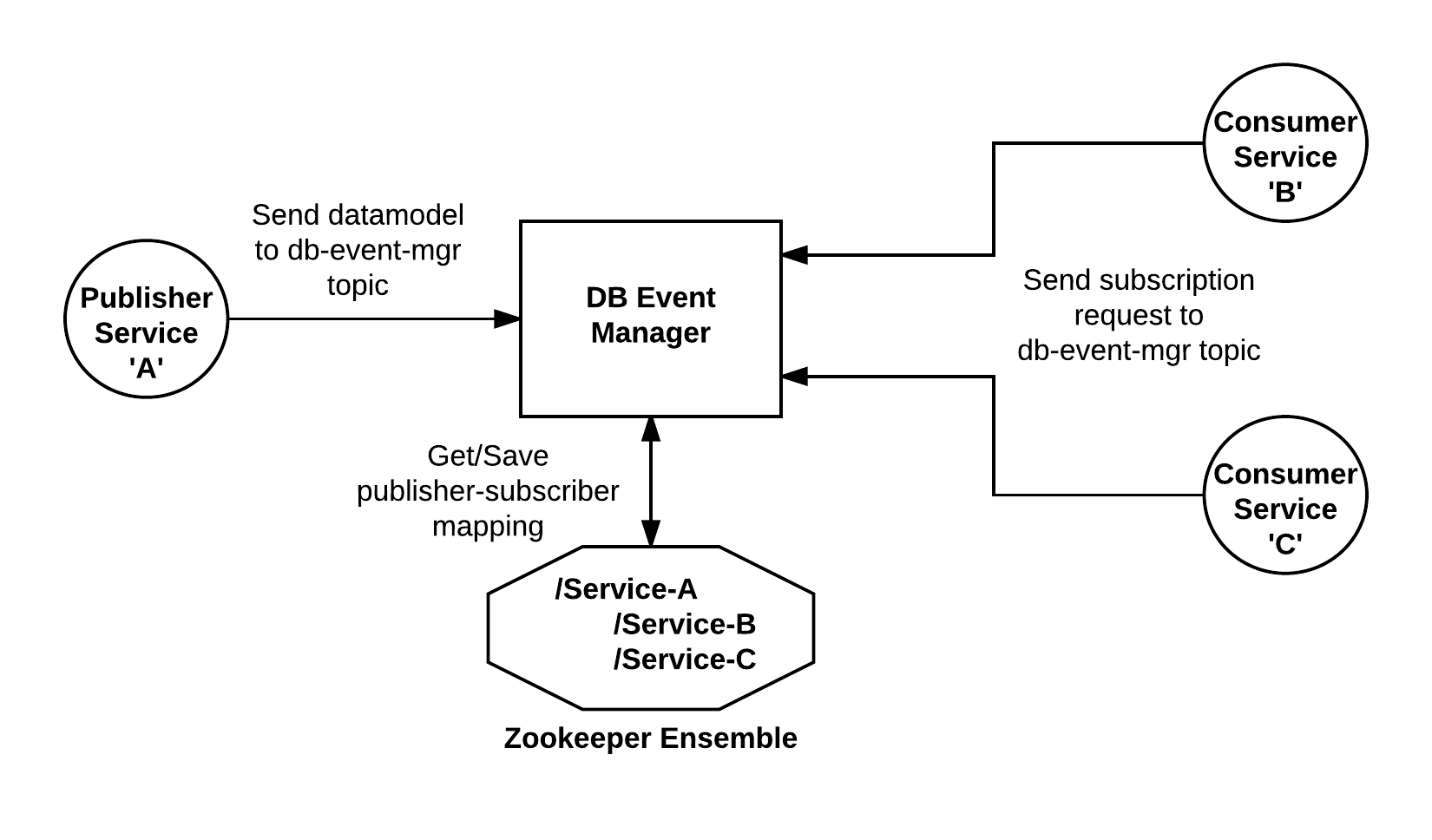
How it works?
- The db-event-manager listens to the
db.event.queuequeue, and also have a connection with a zookeeper ensemble. - If a service needs to be replicated (subsciber-service), it will send a message to the
db-event-exchangewith a routing keydb.event.queue. This message will contain details about the publisher-service it is interested in (source of data replication). The exchange will forward this message to the db-event-manager. - The db-event-manager will save a mapping to the zookeeper via hierarchical nodes.
- When the publisher-service updates any entity, it will send a message to
db-event-exchangewith a routing keydb.event.queue. This message will contain the data model of the entity (for replication), along with the type of CRUD operation. - The db-event-manager will then lookup zookeeper for a publisher-subscriber mapping and accordingly forward the message to respective subscriber-service(s), which will then update it’s database.
Illustration
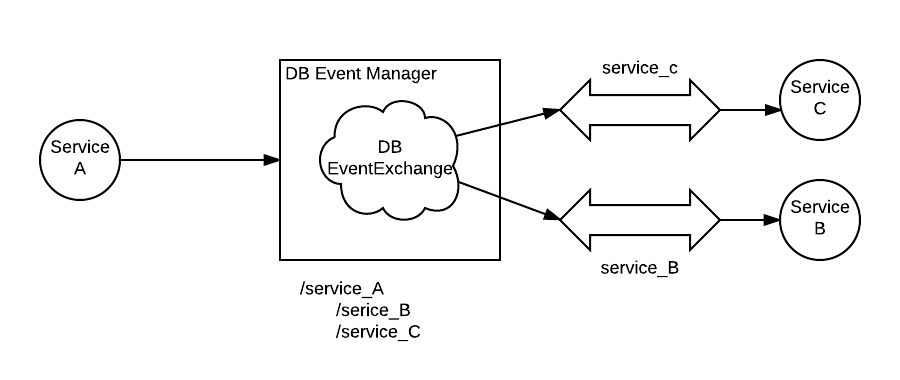
The figure above illustrates this process, where service-c and service-b are subscribed to db changes in service-a.
Using AKKA for performing event-driven-db replication
Akka is a toolkit and runtime for building highly concurrent, distributed, and resilient message-driven applications on the JVM. To understand akka, you primarily need to understand the Actor model. Actors are units of computing, and you communicate with them through messages. Each actor has some local business logic, but it’s more or less a black box to outside code. You can send messages to an actor, or receive a message from an actor, but you can’t access it’s internal logic directly. Each actor has a mailbox which is both a queue and a traffic cop. Messages are sent by other actors, and can accumulate in the queue, but exactly one message can enter an actor’s logic block. That means the code inside the actor is protected from concurrency issues.
If you need parallel processing, you will most likely need a pool of actors that can process messages addressed to a single mailbox. When you use a pool of actors, you can have a single mailbox serviced by multiple actors, but still only one message can enter any given actor. Since communication is done via asynchronous messages, you can scale by shaping your message queues, adding more actors to your pools , or controlling back-pressure (how much mail gets delivered). Actors are generally cheap, and it’s not uncommon for applications to have hundreds of not thousands of actors at any given time.
Possible Solution using Akka
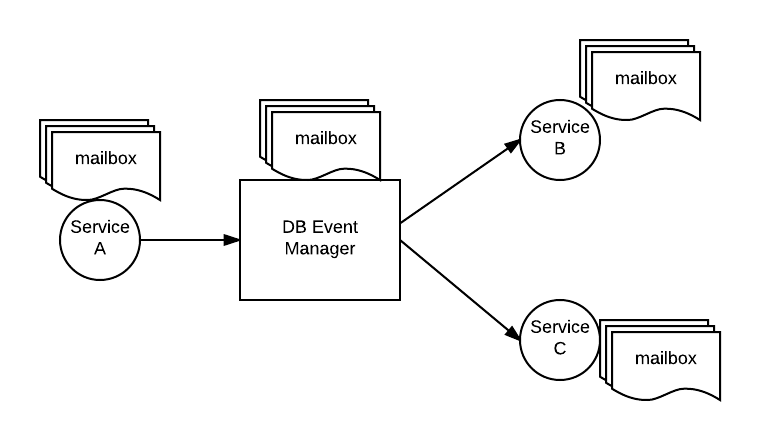
In our case, db-event-manager and other Airavata micro-services both can be considered as actors. The publisher-service will need to send a message to the db-event-manager actor and db-event-manager actor in turn sends messages to corresponding actors based on publisher-consumer mapping saved in Zookeeper. We are still exploring Akka, and identifying good use cases. There are however some challenges, if we decide to use Akka, such as remote actor discovery, actor failure, multiple instances of the same actor(service), etc. We will be doing some more reading about Akka, but in the meanwhile, I have kick-started Akka application development using simple examples (see GitHub link below).
My Git Commits
- Playing around with Akka: The commits are currently made to my personal repository; it can be tracked here.
- Distributed task execution: The commits for this work can be tracked here.
- PEARC’17 paper: The commits made for this purpose can be tracked here.
- Event-Driven Database replication: I am currently commiting my code to Ajinkya’s forked
ajinkya-dhamnaskar/airavatarepository. I then create Pull-Requests to get it merged into the mainapache/airavatarepository.- Commits made to Ajinkya’s forked repository can be tracked here.
- Commits merged to main Airavata repository can be tracked here.